by Filip Gschwandtner | Leave us your feedback on this post!
Updated 11/05/2020: Our Unified Firewall Demo was updated with additional insight, as to how we achieved great results with our solution.
We differentiate generally between a hardware and software firewall. Software firewalls can reside in the userspace (for example, VPP) or the kernel space (for example, NetFilter). These serve as a basis for cloud-native firewalls. The main advantage of software firewalls is the ability to scale without hardware. This is done in the virtual machines or containers (Docker), where these firewalls reside and function from.
One traditional firewall utility in Linux is named iptables. It is configured via command-line and acts as an enforcer of rules and configuration of Netfilter. You can find a great how-to in the Ubuntu Documentation on configuring iptables, which is found pre-installed in most Linux distributions.
For a more performance-oriented firewall solution, you can turn to the evergreen, Vector Packet Processing framework and Access Control Lists (ACLs).
Our CNF Project offers such a cloud-native function - Access Control List (ACL)-based firewall between CNF interfaces with FD.io VPP dataplane and Ligato management plane.
If we have sparked your interest in this solution, make sure to contact us directly. Until then, make sure to watch our CNF project closely - there is more to come!
Firewall Solutions
Multiple solutions mean a wide variety of a user or company is able to choose from. But since each firewall uses a different API, we can almost immediately see an issue with the management of multiple solutions. Some APIs are more fully-fledged than others while requiring various levels of access (high level vs. low-level API) and several layers of features.
At PANTHEON.tech, we found that having a unified API, above which a management system would reside, would make a perfectly balanced firewall.
Cloud-Native: We will be using the open-source Ligato, micro-services platform. The advantage is, Ligato being cloud-native.
Implementation: The current implementation unifies the ACL in FD.io's VPP and the NetFilter in the Linux Kernel. For this purpose, we will be using the open-source VPP-Agent from Ligato.
Separate Layers: This architecture enables us to extend it to any configurable firewall, as seen below.
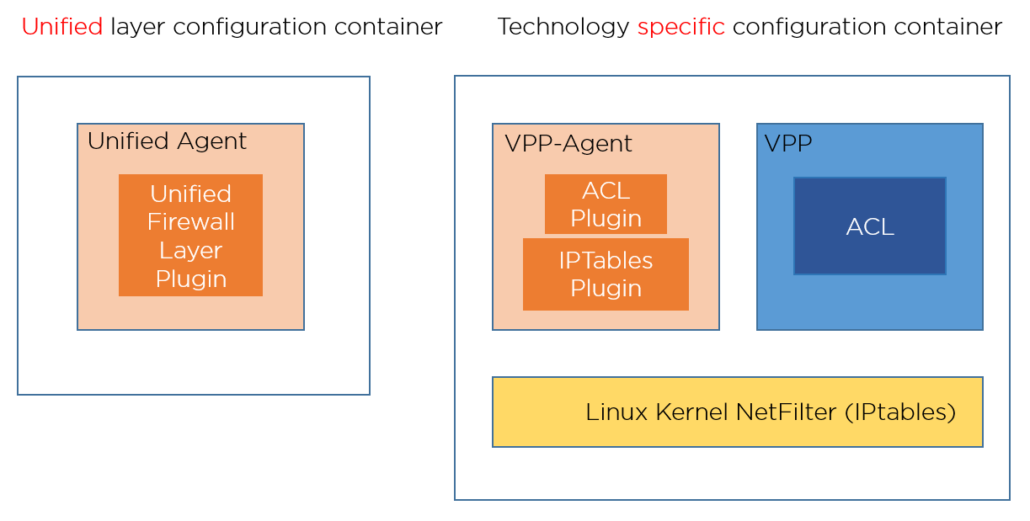
Layer Responsibilities: Computer networks are divided into network layers, where each layer has a different responsibility. We have modeled (proto-model) a unification API and translation to technology-specific firewall configuration. The unified layer has a unified API, which it translates and sends to the technology-specific API. The current implementation is via the VPP-Agent Docker container.
Ligato and VPP-Agent: In this implementation, we make full-use of VPP-Agent and Ligato, via gRPC communication. Each firewall has an API, modeled like a proto-model. This makes resolving failures a breeze.
Resolving Failures: Imagine that, in a cloud, software can end with a fatal error. The common solution is to suspend the container and restart it. This means, however, that you need to set up the configuration again or synchronize it with an existing configuration from higher layers.
Fast Reading of Configurations: There is no need to load everything again throughout all layers, up until the concrete firewall technology. These can be often slow in loading the configuration. Ligato resolves this via the configurations residing in the Ligato platform, in an external key-value storage (ETCD, if integrated with Ligato).
How did we do this?
We created this unifying API by using a healthy subset of all technologies. We preferred simplified API writing - since, for example in iptables, there can be lots of rules which can be written in a more compact way.
We analyzed several firewall APIs, which we broke down into basic blocks. We defined the basic filters for packet traffic, meaning the way from which interface, which way the traffic is flowing. Furthermore, we defined rules, based on the selector being the final filter for rules and actions, which should occur for selected traffic (simple allow/deny operation).
There are several types of selectors:
- L2 (according to the sources MAC address)
- L3 (IP and ICMP Selector)
- L4 (Only TCP traffic via flags and ports / UDP traffic via ports)
The read/write performance of our Unified Firewall Layer solution, was tested using VPP and iptables (netfilter), at 250k rules. The initial tests ended with poor writing speed. But we experimented with various combinations and ended up putting a lot of rules into a few rule-groups.
That did not go as planned either.
A deep analysis showed that the issue is not within Ligato, since task-manager showed that the VPP/Linux kernel was fully working. We made an additional verification for iptables, only by using go-iptables library. It was very slow when adding too many rules in one chain. Fortunately, iptables provides us with additional tools, which are able to export and import data fast. The disadvantage is, that the export format is poorly documented. However, I did an iptables export and insert of data closely before the commit, and imported the data back afterward.
# Generated by iptables-save v1.6.1 *filter :INPUT ACCEPT [0:0] :FORWARD DROP [0:0] :OUTPUT ACCEPT [0:0] :DOCKER - [0:0] :DOCKER-ISOLATION-STAGE-1 - [0:0] :DOCKER-ISOLATION-STAGE-2 - [0:0] :DOCKER-USER - [0:0] :testchain - [0:0] -A FORWARD -j DOCKER-USER -A FORWARD -j DOCKER-ISOLATION-STAGE-1 -A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT -A FORWARD -o docker0 -j DOCKER -A FORWARD -i docker0 ! -o docker0 -j ACCEPT -A FORWARD -i docker0 -o docker0 -j ACCEPT -A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2 -A DOCKER-ISOLATION-STAGE-1 -j RETURN -A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP -A DOCKER-ISOLATION-STAGE-2 -j RETURN -A DOCKER-USER -j RETURN <<insert new data here>> COMMIT
Our Open-Source Commitment
We achieved a speed increase for 20k rules in 1 iptable chain - from 3 minutes and 14 seconds to a few seconds. This showed a perfect performance fix for the VPP-Agent, which we committed to the Ligato VPP-Agent repository.
This also benefited updates, since each updated has to be implemented as a delete and create case (recreated each time). I made it as an optional method with a custom number of rules, from which it applies. Using too few rules can result in great speed with the default approach (via API iptables rule). Now, we have a solution for using a lot of rules as well. Due to the lack of detailed documentation of the iptables-save output format, I decided on turning this option off by default.
The results of the performance test are:
- 25 rule-groups x 10000 rules for each rule-group
- Write: 1 minute 49 seconds
- Read: 359.045785ms
Reading is super-fast, due to all data being in the RAM in the Unified Layer. This means, that it's all about one gRPC call with encoding/decoding.
If we have sparked your interest in this solution, make sure to contact us directly.

![[Case Study] Engineering an SDN solution for a global vendor](https://pantheon.tech/wp-content/uploads/2026/06/use-case-sdn.jpg)
![[How-To] Evaluate an Enterprise Network Orchestration & Automation Platform](https://pantheon.tech/wp-content/uploads/2026/05/evaluate-orch-platform.jpg)