

What is VXLAN (Virtual Extensible LAN)?
In today’s data-driven world, data centers are the lifeblood of modern businesses, providing the infrastructure for the storage, processing and flow of information. As businesses expand and generate more data, data center managers face the daunting task of...![[What Is] SONiC (Software for Open Networking in the Cloud)](https://pantheon.tech/wp-content/uploads/2023/10/jd_1200x627-1080x627.png)
[What Is] SONiC (Software for Open Networking in the Cloud)
SONiC (Software for Open Networking in the Cloud) is an open-source network operating system (NOS) based on Linux designed to revolutionize the way networks are managed and operated. Born out of the need for flexibility and scalability in data center networking,...
What is Network Address Translation (NAT) ?
As the number of devices accessing the internet has grown exponentially over the years, the supply of available IPv4 addresses has not been able to keep pace. We now find ourselves on the brink of depletion, with the pool of unique IPv4 addresses nearing exhaustion....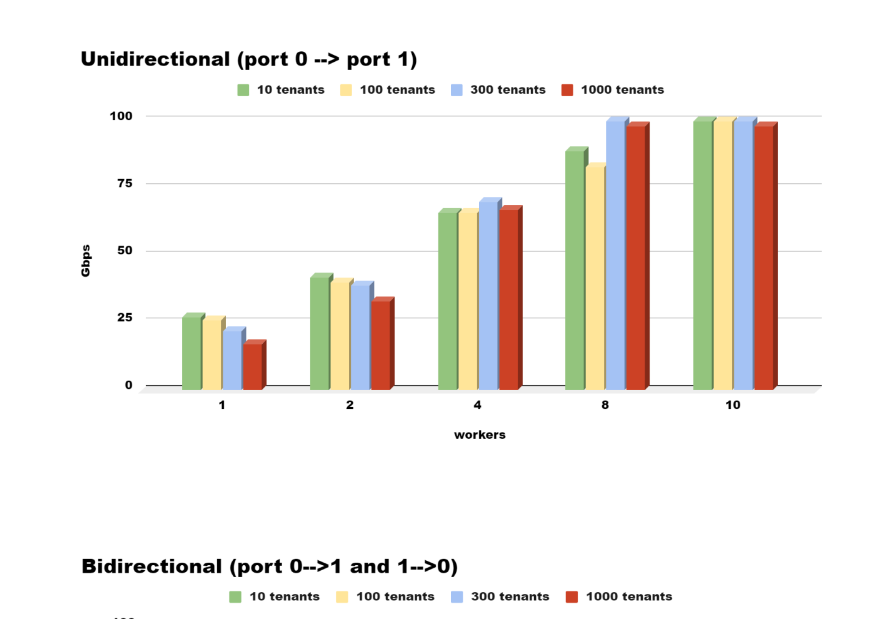
Empowering Service Providers Provider Edge: PANTHEON.tech’s StoneWork Multi Service Router leveraging Intel’s latest Xeon CPU – Performance / Scale Test
In the rapidly evolving digital landscape, service providers face increasing challenges in meeting customer demands. These in turn are placing ever growing strains on the network capabilities, with traditional equipment solutions no longer able to suffice delivering...
What is Virtual Local Area Network (VLAN) / 802.1.q ?
In the world of computer networking, achieving optimal resource utilization, network scalability, effective network management and security is key. A common approach to attaining these objectives is utilizing virtualization. By utilizing virtualization we can connect...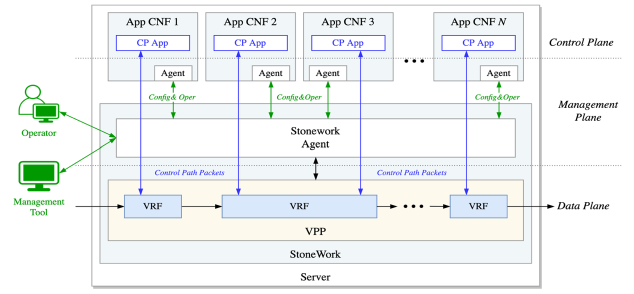
What is Virtual Routing and Forwarding (VRF) ?
In traditional network setups, the issue of network scalability becomes a significant challenge as networks grow and new services are introduced. The usual approach often involves setting up separate physical hardware for each new network or service, resulting in...
OpenDaylight Project Celebrates 10 Years (of Active Development)
The OpenDaylight Project is an open-source software-defined networking (SDN) controller platform that has been in active development for 10 years. Since its launch in 2013, the project has grown and evolved significantly, and it has become one of the most popular SDN...
PANTHEON.tech at the OCP Regional Summit Prague 2023
We are proud to announce that our Chief Product Officer, Miroslav Miklus, will be speaking at the upcoming OCP Regional Summit 2023 in Prague already in May! Don’t miss out and come see him speaking on the SONiC Enterprise Features topic, where he ‘ll...