What is XDP?
XDP (eXpress Data Path) is an eBPF (extended Berkeley Packet Filter) implementation for early packet interception. Received packets are not sent to kernel IP stack directly, but can be sent to userspace for processing. Users may decide what to do with the packet (drop, send back, modify, pass to the kernel). A detailed description can be found here.
XDP is designed as an alternative to DPDK. It is slower and at the moment, less mature than DPDK. However, it offers features/mechanisms already implemented in the kernel (DPDK users have to implement everything in userspace).
At the moment, XDP is under heavy development and features may change with each kernel version. There comes the first requirement – to run the latest kernel version. Changes between the kernel version may not be compatible.
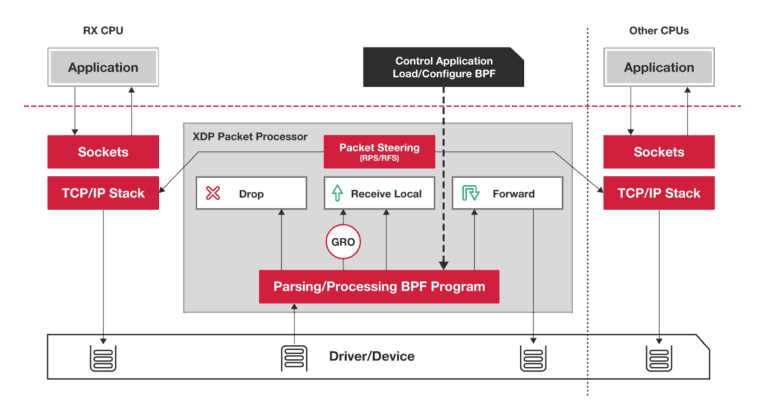
IO Visor description of XDP packet processing
XDP Attachment
The XDP program can be attached to an interface and can process the RX queue of that interface (incoming packets). It is not possible to intercept the TX queue (outgoing packets), but kernel developers are continuously extending the XDP feature-set. TX queue is one of the improvements with high interest from the community.
XDP program can be loaded in several modes:
- Generic – Driver doesn’t have support for XDP, but the kernel fakes it. XDP program works, but there’s no real performance benefit because packets are handed to kernel stack anyways which then emulates XDP – this is usually supported with generic network drivers used in home computers, laptops, and virtualized HW.
- Native – Driver has XDP support and can hand then to XDP without kernel stack interaction – Few drivers can support it and those are usually for enterprise HW
- Offloaded – XDP can be loaded and executed directly on the NIC – just a handful of NICs can do that
XDP runs in an emulated environment. There are multiple constraints implied, which should protect the kernel from errors in the XDP code. There is a limit on how many instructions one XDP can receive. However, there is a workaround in the Call Table, referencing various XDP programs that can call each other.
The XDP emulator checks the range of used variables. Sometimes it’s helpful – it doesn’t allow you to access packet offset higher than already validated by packet size.
Sometimes it is annoying because the packet pointer can be passed to a subroutine, where access may fail with out of bounds access even if the original packet was already checked for that size.
BPF Compilation
Errors reported by the BPF compiler are quite tricky, due to the program ID compiled into byte code. Errors reported by that byte code usually do not make it obvious, which C program part it is related to.
The error message is sometimes hidden at the beginning of the dump, sometimes at the end of the dump. The instruction dump itself may be many pages long. Sometimes, the only way how to identify the issue is to comment out parts of the code, to figure out which line introduced it.
XDP can’t (as of November 2019):
One of the requirements was to forward traffic between host and namespaces, containers or VMs. Namespaces do the job properly so, XDP can access either host interfaces or namespaced interfaces. I wasn’t able to use it as a tunnel to pass traffic between them. The workaround is to use a veth pair to connect the host with a namespace and attach 2 XDP handlers (one on each side to process traffic). I’m not sure, whether they can share TABLES to pass data. However, using the veth pair mitigates the performance benefit of using XDP.
Another option is to create AF_XDP socket as a sink for packets received in the physical interface and processed by the attached XDP. But there are 2 major limitations:
- One cannot create dozens of AF_XDP sockets and use XDP to redirects various traffic classes into own AF_XDP for processing because each AF_XDP socket binds to the TX queue of physical interfaces. Most of the physical and emulated HW supports only a single RX/TX queue per interface. If there’s one AF_XDP already bound, another one will fail. There are few combinations of HW and drivers, which support multiple RX/TX queues but they have 2/4/8 queues, which doesn’t scale with hundreds of containers running in the cloud.
- Another limitation is, that XDP can forward traffic to an AF_XDP socket, where the client reads the data. But when the client writes something to AF_XDP, the traffic is going out immediately via the physical interface and XDP cannot see it. Therefore, XDP + AF_XDP is not viable for symmetric operation like encapsulation/decapsulation. Using a veth pair may mitigate this issue.
XDP can (as of November 2019):
- Fast incoming packet filtering. XDP can inspect fields in incoming packets and take simple action like DROP, TX to send it out the same interface it was received, REDIRECT to other interface or PASS to kernel stack for processing. XDP can alternate packet data like swap MAC addresses, change ip addresses, ports, ICMP type, recalculate checksums, etc. So obvious usage is for implementing:
- Filerwalls (DROP)
- L2/L3 lookup & forward
- NAT – it is possible to implement static NAT indirectly (two XDP programs, each attached to own interface, processing and forwarding the traffic out, via the other interface). Connection tracking is possible, but more complicated with preserving and exchanging session-related data in TABLES.
by Marek Závodský, PANTHEON.tech
AF_XDP
AF_XDP is a new type of socket, presented into the Linux Kernel 4.18, which does not completely bypass the kernel, but utilizes its functionality and enables to create something alike DPDK or the AF_Packet.
DPDK (Data Plane Development Kit) is a library, developed in 2010 by Intel and now under the Linux Foundation Projects umbrella, which accelerates packet processing workloads on a broad pallet of CPU architectures.
AF_Packet is a socket in the Linux Kernel, which allows applications to send & receive raw packets through the Kernel. It creates a shared mmap ring buffer between the kernel and userspace, which reduces the number of calls between these two.
At the moment XDP is under heavy development and features may change with each kernel version. There comes the first requirement, to run the latest kernel version. Changes between the kernel version may not be compatible.
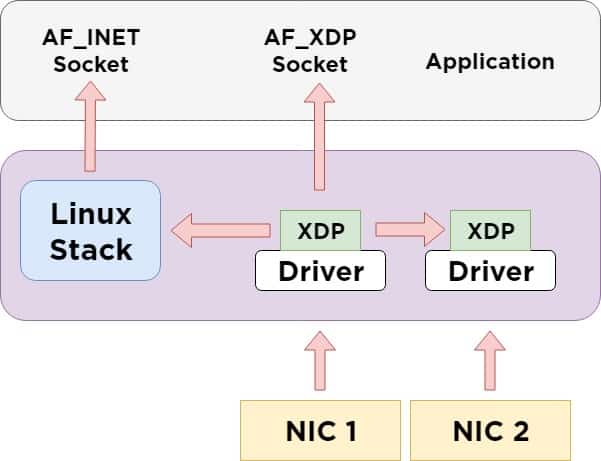
As opposed to AF_Packet, AF_XDP moves frames directly to the userspace, without the need to go through the whole kernel network stack. They arrive in the shortest possible time. AF_XDP does not bypass the kernel but creates an in-kernel fast path.
It also offers advantages like zero-copy (between kernel space & userspace) or offloading of the XDP bytecode into NIC. AF_XDP can run in interrupt mode, as well as polling mode, while DPDK polling mode drivers always poll – this means that they use 100% of the available CPU processing power.
Future potential
One of the potentials in the future for an offloaded XDP (being one of the possibilities of how an XDP bytecode can be executed) is, that such an offloaded program can be executed directly in a NIC and therefore does not use any CPU power, as noted at FOSDEM 2018:
Because XDP is so low-level, the only way to move packet processing further down to earn additional performances is to involve the hardware. In fact, it is possible since kernel 4.9 to offload eBPF programs directly onto a compatible NIC, thus offering acceleration while retaining the flexibility of such programs.
Decentralization
Furthermore, all signs lead to a theoretical, decentralized architecture – with emphasis on community efforts in offloading workloads to NICs – for example in a decentralized NIC switching architecture. This type of offloading would decrease costs on various expensive tasks, such as the CPU itself having to process the incoming packets.
We are excited about the future of AF_XDP and looking forward to the mentioned possibilities!
For a more detailed description, you can download a presentation with details surrounding AF_XDP & DPDK and another from FOSDEM 2019.
Update 08/15/2020: We have upgraded this page, it’s content and information for you to enjoy!
You can contact us at https://pantheon.tech/
Explore our Pantheon GitHub.
Watch our YouTube Channel.

![[How-To] Evaluate an Enterprise Network Orchestration & Automation Platform](https://pantheontech1.b-cdn.net/wp-content/uploads/2026/05/evaluate-orch-platform.jpg)